
The Ferranti
ORION
Computer
System
The Ferranti
ORION
Computer
System
by H. P. Goodman
The Orion time-sharing system—as originally envisaged—may lead to inefficient running with certain combinations of programs. A simulation program has been written for Sirius to investigate methods of improving the time-sharing, and also to examine the advantages of time-sharing between two branches of the same program. This paper is based on a talk given to The British Computer Society in London on 15 February 1961.
Orion is a medium-to-large computer with full time-sharing facilities. The system works partly by hardware and partly by program, so it is possible to make modifications in the light of experience.
There is virtually no limit to the number of programs that can be run simultaneously. In the time-sharing system originally envisaged, these programs are arranged in a list with those programs that arc severely limited by peripheral equipment at the top of the list, and programs that are mainly mill-limited at the bottom of the list - the term "mill-limited" is used to describe programs that are calculating most of the time and only do occasional peripheral transfers.
There are two types of interruption:
(a) time-sharing interruptions;
(b) monitoring interruptions.
Monitoring interruptions are those that cause entry to the organization and monitor program for such events as program or peripheral-equipment failures or intentional entries to request special actions - they will not be considered further in this paper.
Time-sharing interruptions are of four types:
(i) Peripheral lock-out. - This occurs when a program refers to a busy (or disengaged) peripheral device. In some cases several peripheral devices may be connected to a common control unit - for instance, paper-tape readers and punches. If one of these devices is busy then the others cannot be used, so a program referring to such a device will be locked-out until the control unit is free.
(ii) Core-store lock-out. - This occurs when a program refers to a core store location which is involved in a reading transfer, or attempts to write to a location involved in a writing transfer.
(iii) End of transfer. - This occurs when a peripheral device has completed a transfer. This causes an interruption, so that a program which has been waiting for that device, or its control unit, can be re-entered.
(iv) When one second has elapsed since the last interruption. This is for protection against certain rare cases where an end-of-transfer interruption is missed due to two transfers ending almost simultaneously; a low priority program might be entered and not get interrupted, although a higher priority program is ready to run.
In each case the link (i.e. return address) and requirement of the program just left are stored, and the program cannot be re-entered until its requirement is free. In case (i) the requirement is the peripheral device referred to, in case (ii) it is the core store location referred to, and in cases (iii) and (iv) there is no requirement.
The form of the simple time-sharer, to be referred to as Time-sharer Mk. 1, is illustrated in Fig. 1. The programs at the top of the list initiate many peripheral transfers and spend most of the time locked out on peripheral devices (or the core store), thus allowing the lower, mill-limited programs to proceed.
Difficulties arise with the Mk. 1 time-sharer if two programs use the same peripheral device. This can in fact only happen in the case of the drum, but the same effect occurs if two programs use devices connected to the same control unit. Consider the following simple case - with just two programs in the machine. Program A is drum-limited - e.g. a program that requires a random-access store larger than the available core store. Program B is mill-limited - it calculates nearly all the time but occasionally requires access to the drum to write up some results or to read down some fresh data. These programs appear compatible and should between them keep both the mill and the drum busy full time.
What happens, however, is that the programs interfere. Program A is entered and uses the drum. It then tries to use the drum again, gets locked out and program B is entered. Program B calculates until A's first transfer is finished, when there is an end of transfer interruption and A is entered. A does its second transfer and gets locked out on attempting to initiate a third - letting B in again. This process continues until B tries to use the drum. B then finds that the drum is busy doing A’s transfer and B is therefore also locked out. The computer is now idle until A's transfer is finished: A then initiates another transfer and is subsequently locked out. B thus still fails to get in as it is still waiting for the drum. B never gets in again and the computer is idle between A's transfers.
(i)
Store link and requirement of program just left
(ii) Scan programs in fixed order to find first one ready to go
(iii)
Enter program found
Fig. 1. Orion – Simple time-sharer
To avoid this difficulty it is necessary that B should be able to get at the drum whenever it requires it; in general the requirement is that a program which makes little use of the mill should normally be entered if ready to go, but if a mill-limited program is waiting for a device it only uses occasionally then it should be entered. Considerable thought was given to the best method of achieving this and it was eventually decided to introduce the concept of a chronological peripheral queue (Fig. 2). When a program is interrupted the time-sharer inserts the program at the end of this queue if the interruption was caused by a peripheral lock-out. The time-sharer now scans the peripheral queue, though it will probably only find a program ready to go in the queue if the interruption was caused by end of transfer. If there is no program in the peripheral queue that is ready to go, the time-sharer now scans the normal list as in Mk. 1. This time-sharer will be called Mk. 2; it ensures that every program gets a chance to initiate its transfer in turn and hence that no program can lock-out another one permanently.
|
Store link and requirement of program just left Is requirement Peripheral Lock-out? If so, insert program at end of peripheral queue Scan peripheral queue
|
|
|
FOUND Delete entry from peripheral queue Move subsequent entries up one Enter program
|
NOT FOUND Scan main list (i.e. fixed order) Enter program found |
Fig.2. Orion – Complex time-sharer
The consequences of the Mk. 2 time-sharer are far from obvious when several, possibly complicated, programs are running simultaneously; so we decided to write a simulator. It is unnecessary for the simulator to simulate the Orion instruction code in detail, only the time-sharing properties are needed.
A Sirius computer was available at the Ferranti London
Computer Centre, Newman Street, and proved very suitable for the purpose.
Sirius is a small decimal computer with 1,000 words of storage (which proved
sufficient), paper tape input and output, and a digital decimal display. The
Sirius initial orders accept instructions written as four decimal digits
followed by space and a six-digit address - the latter may be omitted if zero. It
is therefore convenient to write the simulated instructions in the same form to
avoid writing a special input routine. The instruction code used is shown in
Fig. 3. There are assumed to be up to nine peripheral
controls numbered 1-9, but output only occurs for up to the highest-numbered
control used. The interval between outputs is set on the decimal keyboard in
milliseconds; the output consists of the time used by each program on the mill
and on each control. Up to nine programs can be run simultaneously and all
programs must terminate by an unconditional jump or a suspend instruction. The
order of the programs on the input tape is the order of priority assumed - each
program being terminated by L. Thus the simple case described above (taking
control 1 as the drum) can be represented as follows:
→0000 10
↑ 0010 100
←0102
L
→0000 100
↑ 0010 10
←0102
L
This version of the simulator does not simulate core-store lock-outs as it is chiefly intended to study the effects of peripheral lock-outs. Simulator Mk. 1.1 uses time-sharer Mk. 1, and Mk. 1.2 time-sharer Mk. 2.
The program given above was run on the simulators Mks. 1.1 and 1.2. With 1.1 the second program soon got locked out on the drum and the efficiency of mill utilisation was 10%. With Mk. 1.2, the improvement was to 45% which is still disappointing. The reason is as follows: program A is locked out on the drum and therefore has an entry in the peripheral queue, when program B gets locked out it is entered second in the peripheral queue; B therefore has to wait until A completes its current transfer and does one more transfer before B gets in. This can be cured by the following modification: we introduce a bottom priority program, called program G, which is entered whenever no other program is able to run. Program G simply takes the bottom entry from the peripheral queue and puts it to the top—thus letting B in as soon as A's transfer is complete. This device produces an improvement in every case run so far. The time-sharer with program G is Mk. 3 and is used in the simulator Mk. 1.3. In the above case the mill utilisation with Mk. 1.3 becomes 58%. This low figure is largely due to the accident of the numbers in the program - it so happened that B always tried to initiate a transfer 1 msec after A had started one, so that it had to wait 99 msec before it got in. The case was re-run with B referring to the drum less often, and the mill utilisations for the three time-sharers became 10%, 78% and 89%.
|
0000 N Calculate for N msec.
00a0 N Start a transfer on
peripheral control
a lasting 01ab Unconditional jump back ab instructions. 01ab N Jump back ab instructions, counting up to N . 0200 N Reset count in previous instruction to N. 0300 Suspend this program. |
Fig. 3. Simulator Mk. 1 instruction code
Several more complicated cases were run on the various versions of the simulator and two of them are described below.
|
TS |
ORDER |
MILL |
DRUM |
PT |
|
|
|
% |
% |
% |
|
1 |
ABC |
25 |
99 |
12 |
|
1 |
BAC |
96 |
2 |
98 |
|
2 |
ABC |
91 |
96 |
91 |
|
2 |
BAC |
93 |
95 |
90 |
|
3 |
ABC |
94 |
97 |
91 |
|
3 |
BAC |
94 |
95 |
92 |
|
program A — Drum limited outputs occasionally. program B — Input routine, tape limited — writes to drum occasionally. program C — Base load — uses drum occasionally. |
||||
Table 1 gives the results for case 2 where there are three programs, all of which use the drum and two of which use paper tape - it is assumed that the output punch used by program A and the tape reader used by program B are on the same control unit. The programs were run with all three time-sharers (shown in the first column under TS), and in the two orders of priority ABC and BAC (there is no point in trying program C as top priority as it would never get locked out). With the Mk. 1 time-sharer in the order ABC, programs B and C both get locked-out on the drum after an initial period, and the low mill and paper tape utilisation figures reflect the utilisation by A alone. In the order BAC program A gets locked out on paper tape, but B and C go - hence the low drum utilisation figure. With time-sharers 2 and 3 all three programs go and the order of priority makes little difference. Note that the figures for time-sharer 3 are slightly better than those for time-sharer 2. As the order of priority between A and B makes little difference the allocation of priority becomes less critical; since it is often difficult to allocate priorities accurately this is itself an argument in favour of the complex time-sharer.
The third case is shown in Table 2 and is meant to illustrate a typical commercial load. The main job is program B, which is up-dating a low activity file and is usually magnetic-tape limited. When program B has to process an amendment it has to get another chapter of program from the drum and obey it. Program A is a pseudo off-line job which is printing out a magnetic tape - it uses virtually no mill-time and is heavily printer-limited. With just these two programs it made very little difference which time-sharer was used since the programs do not interfere with each other to any significant extent. The mill is used less than half the time as both programs are peripheral-equipment limited. If, however, a base-load program is added this goes very much better with the complex time-sharer, and the mill is used over 90%, of the time at the expense of a slight reduction in magnetic tape efficiency. The results from time-sharer Mk. 3 were almost identical to those from Mk. 2 and they have therefore been omitted from Table 2.
|
TS |
MILL |
DRUM |
MAGNETIC |
PRINTER |
|
1 2 |
% 45 46 |
% 28 28 |
% 79 79 |
% 99 98 |
|
WITH BASE LOAD |
||||
|
1 |
76 |
35 |
79 |
99 |
|
program A — Magnetic tape to line printer. program B — File updating — Low activity
|
||||
On Orion it is possible to use time-sharing between two branches of the same program. It is usual to regard one branch as the master and the other as a slave - the slave is usually operating a peripheral device. A good example where this technique is useful is a program producing information to be printed on a line printer. The program may take 1 second per case, at the end of which ten lines are available to be printed - these all becoming available simultaneously. The printer operates at ten lines per second, so one wishes to keep the mill and the printer both fully occupied. If one tries to feed out these lines one after the other, one will be locked out on each line after the first so there is very little advantage from the autonomous transfer facilities. An alternative is to scatter print instructions through the program at approximately 100 msec intervals but this will rarely be satisfactory. The solution is to have a slave program - the master program fills a buffer in the core store and the slave empties it using time-sharing, while the master is doing the next case. Special, instructions are provided to ensure that the two branches of the program do not get out of step.
A more complicated case is the file updating job discussed above (Table 2). The processing of the file keeps up with the magnetic tape (and normally waits for it) unless there is an amendment. Then the tape is held up until the amendment has been processed and the program is ready to initiate another transfer. What happens in fact is that there are three areas of core store the size of the length of tape block being used. The program initiates an input and an output tape transfer (which proceed simultaneously on the assumption that two tape controls are available) and then processes the block just read. The tape is thus held up if the two tape transfers have been completed before the master has finished processing.
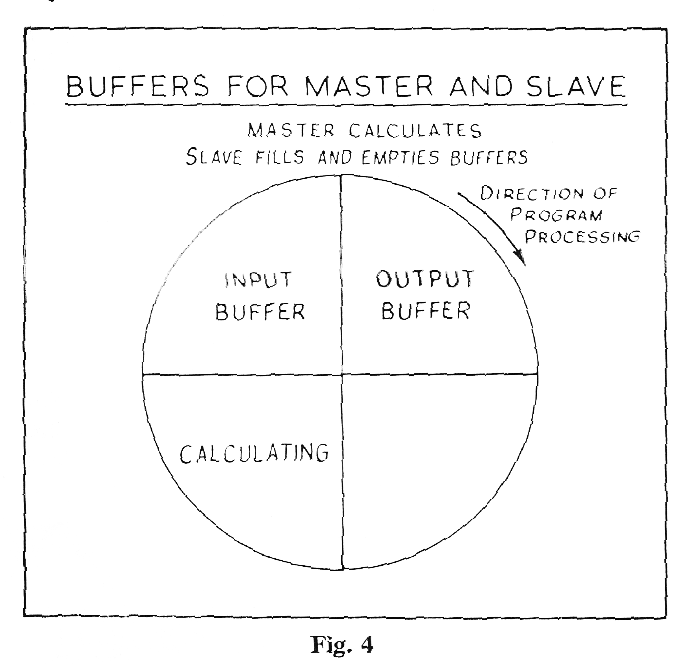
If one uses the master-slave technique for this problem one has four or more buffers instead of three (Fig. 4). When there are no amendments the master program is processing the block just read in and there is one block which has been processed and is waiting to be fed out by the slave. When the master finishes processing each block it is suspended until the slave has produced another block to be processed. When an amendment occurs the master is still processing when the slave has finished its current transfer so the slave proceeds to do the input and output of one further block as there is a spare buffer available. If the processing has been finished before these transfers then the master can carry on with the next block. If no second amendment arrives in the next few records the master will catch up and the tape will be kept busy all the time.
If one uses more than four buffers in the above problem the chance of the master program getting so far behind the slave that the tape has to wait is reduced. However, assuming a fixed area of store available for buffers, the length of each buffer is reduced as their number increases, and the tape efficiency suffers accordingly - long blocks on tape are more efficient as there is a fixed length of inter-block gap. It was decided to carry out some experiments on Sirius to determine the optimum number of buffers, and the simulator was rewritten accordingly. The revised instruction code is shown in Fig. 5. The simulation has been made more realistic by the inclusion of core-store lock-outs. There are nine core store regions numbered 1-9, and a program is locked out if it refers to a region involved in a transfer in the same or another program. If two programs are in the master-slave relationship they will use the same core store regions - independent programs will have their own core store regions (this is not checked in the simulator but is checked by hardware in Orion). Reference to core store region 0 will cause no lock-out - this makes it simpler to consider cases where core store lock-outs are unimportant. The 04 instruction is the link between the master and the slave. A counter in location N (where N is a Sirius store location) has one subtracted from it by the master and one added to it by the slave each time round the loop. If the master finds it negative the slave is getting behind and the master suspends itself. A similar instruction is used by the slave to switch the master on again at the appropriate moment.
|
000b N Calculate for N msec using core store region b 00ab N Start a transfer on control a and core store region b lasting N msec. If b = 0 no core store lock-out. 01ab Unconditional jump back ab instructions. 01ab N Jump back ab instructions, counting up to N . 0200 N Reset count in previous instruction to N. 0300 Enter Sirius machine instructions at next instruction. 04a0 N Reactivate program a if suspended. Suspend this program if c(N) < 0. 0500 Suspend. Not reactivable by 04 instruction. |
Fig. 5. Simulator Mk. 2 instruction code
There is also a facility to enter Sirius machine instructions - these are allocated a range of store locations which they may use and return to the simulator by an appropriate jump. Their main use is to calculate markers used in the 04 instructions, but they have other applications which make the simulator more flexible - for instance genuine conditional jumps can be used and pseudo-random numbers calculated to give the effect, for instance, of a genuine random 2% amendment rate instead of one amendment every fifty records. They are also necessary to modify through a series of buffers by generating and planting suitable 00 instructions.
The file updating job with master and slave was run on the simulator with 3, 4, 5, and 6 buffers and with two different amendment rates - the results are given in Table 3. In each case, 1,500 core store locations were assumed to be available for buffers, and the resultant buffer lengths are given in the third column. The case with three buffers is effectively the same as if master-slave techniques were not used. In each case the same number of records were processed, and the fourth column gives the total elapsed time in each case.
Table 3
Results of Master and
Slave Buffering
|
AMENDS |
BUFFERS |
BUFFER LENGTH |
TOTAL |
TAPE |
BASE |
|
% |
|
WORDS |
SEC |
SEC |
SEC |
|
2 |
3 |
500 |
13.2 |
19.7 |
4.3 |
|
2 |
4 |
375 |
12.9 |
21.9 |
3.6 |
|
2 |
5 |
300 |
13.1 |
22.8 |
3.3 |
|
2 |
6 |
250 |
13.4 |
23.2 |
3.4 |
|
5 |
3 |
500 |
16.9 |
19.7 |
6.0 |
|
5 |
4 |
375 |
16.5 |
22.0 |
5.4 |
|
5 |
5 |
300 |
16.7 |
23.0 |
5.2 |
|
5 |
6 |
250 |
16.6 |
23.3 |
4.8 |
|
Order of programs: (a) Tape to
printer; (b) Slave; |
|||||
The results were disappointing in the sense that they show that the master-slave technique is not really worth while in this case. The total time was only fractionally better for four buffers than three; in both cases five and six buffers were worse than four. The fifth column gives the total tape-control time used (assuming two tape controls). This increases with the number of buffers due to the reduced efficiency of using shorter tape blocks, but note that even with six buffers the two controls are still not used full time so the tape is still held up on occasions. The last column gives the time left for a base-load program - this may not exist, as in many installations no suitable program is available, and the main load probably uses all the core store. The gain obtained by the master-slave technique is not worth the trouble taken.
Table 4
Results of Compiler
Simulation
|
CORE REFS. |
DRUM REFS. |
TAPE REFS. |
METHOD |
TOTAL TIME |
MILL USE |
|
% |
% |
% |
|
SEC |
% |
|
40 |
40 |
20 |
One program |
44.4 |
5.1 |
|
40 |
40 |
20 |
Master and slave |
39.4 |
5.8 |
|
25 |
70 |
5 |
One program |
19.9 |
12.0 |
|
25 |
70 |
5 |
Master and slave |
17.1 |
14.1 |
Another case investigated was a compiling routine. This required random access to a large number of words; some in the core store, some on the drum, and the remainder on magnetic tape; a tape search is required for the latter. For reading from the tape it is necessary to hold up the master, but writing can be done by a slave. The effects of running the problem as one program or as master and slave were investigated in the two cases of core store references, drum references, and tape references in the ratios 40 : 40 : 20 and 25 : 70 : 5 - the results are given in Table 4. Once again the same amount of work was done in each case and the total times are given in the fifth column. They show that the savings made by the master and slave technique are appreciable in this case; the large reduction in time in the last two rows show that the program is heavily limited by tape searches. The last column shows that this compiler uses only a small proportion of mill time and it is therefore highly desirable to run a base-load program with it if a suitable one can be found. However, the advantages of using the master-slave technique are sufficient to make it worth while in this case.
In conclusion, it appears that time-sharing is a very worth while facility, but that its detailed effects are so complicated that it is essential to use simulation on a computer to trace them. When Orion is working, these predictions will have to be tested in practice, but it will still be necessary to use some sort of simulator - possibly on Orion itself - to obtain detailed statistics of the performance of the various programs.
* * * *
The author wishes to thank Messrs. Ferranti Ltd. for permission to publish this paper.